







Legendshop 标准产品
为企业开拓全渠道电子商务销售通路,实现互联网转型升级
-
 Java技术
Java技术
-
 独立部署
独立部署
-
 源码授权
源码授权
-
 多端体验
多端体验




专业定制的新零售解决方案
专业定制新零售解决方案,解决您各种零售场景的需求和问题
-
 产品优势
产品优势
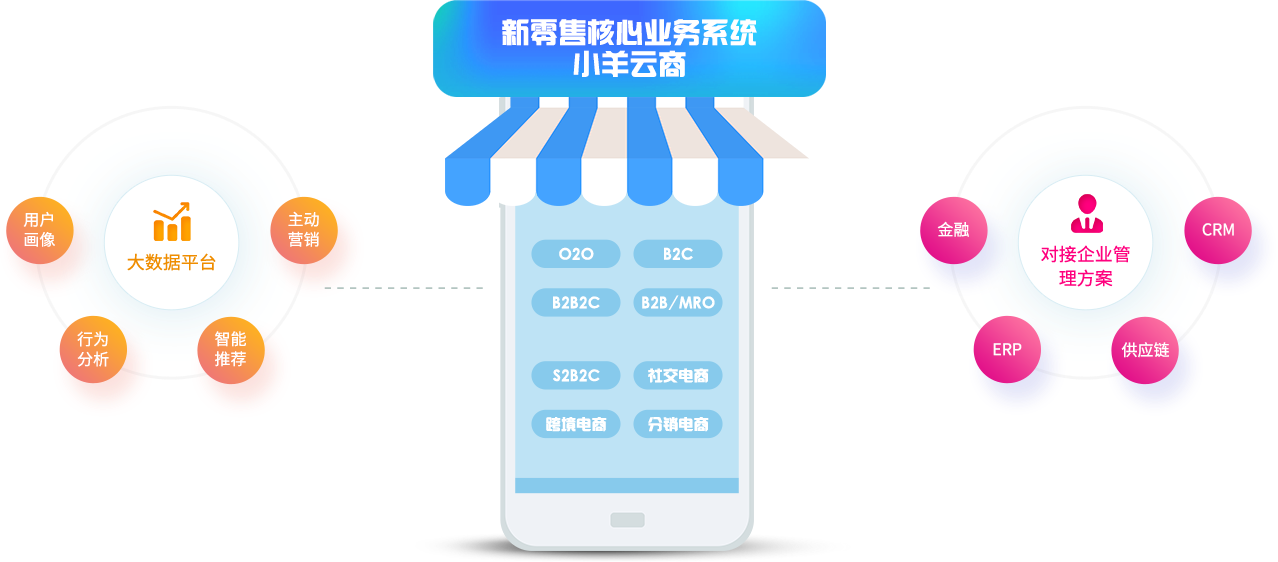
专注新零售新分销的电商系统, 满足零售商、分销商的业务发展 需要,PC、微信、APP三站合一
-
 方案优势
方案优势
针对客户个性化需求打造专属解 决方案,应对行业、角色不同的 业务功能需求
-
 技术优势
技术优势
全java布局,稳定安全,系统可 靠性高;开源框架,源码开源无 封装,负载均衡+集群部署
-
 服务优势
服务优势
资深产品经理全程1对1服务,免 费的成本不菲的源码培训,全面 细致的产品使用培训
Industry 应用行业
抓住行业特性,打造垂直行业应用,满足各类分销、零售行业需求
-
 食品生鲜
食品生鲜
-
 家居装饰
家居装饰
-
 母婴用品
母婴用品
-
 3C数码
3C数码
-
 服装饰品
服装饰品
-
 个护美妆
个护美妆
-
 医护保健
医护保健
-
 其他行业
其他行业
Cases 成功案例
服务生态,助力成长,legendshop是企业互联网转型的最佳选择
 南钢鑫智链MRO平台
南钢鑫智链MRO平台
南京钢铁联合有限公司是由南京钢铁集团有限公司与上海复星集团等共同合资成立的江苏省特大型钢铁企业
 提供解决方案
提供解决方案
项目基于朗尊软件Spring Cloud 微服务架构的设计理念通过和其他业务系统有机的结合,解决企业采购痛点,整合产业供应链的数据,为企业利润率贡献大的客户提供更加个性化的服务,为企业的ERP和经营决策支持提供强有力的数据和信息支撑,提供一个集服务、管理和经营决策分析与支持为一体的综合服务网络平台,提高企业整体的社会经济效益和市场竞争力;采用企业采购审批,批量采购做法;对接南钢内部的招标部系统, 中标商家可以上架商品;对接南钢ERP系统,打通内部企业物料管理;对接上上签合同和征信系统, 让合同更加有保障;对接中储物流, 让商家更容易选择物流和达到物流追踪
 实施效果
实施效果
项目正在进行中

上汽大众B2B2C商城系统
上汽大众成立于1985年,是一家中德合资企业,也是国内大规模的现代化轿车生产基地之一。总部位于上海安亭,目前拥有朗逸、途观、桑塔纳、帕萨特和斯柯达品牌等系列产品。
提供商城解决方案
项目基于朗尊软件Spring Cloud 微服务架构的设计理念进行构建的 B2B2C 多渠道分销平台的新零售解决方案;提供一站式互联网汽车营销平台的解决方案 ,从线上揽客、线上预订订单、涵盖用户的车主认证、汽车维护保养等全流程的汽车生活服务体验;O2O方案(网上预约,4S点体验试车或者购车,或者售后);对接上汽大众的SCRM销售管理系统,ERP企业内部生产系统,VMS订单对接
实施效果
推出了上汽大众汽车商城,加强销售网络的可控性,做到产品研发、网络销售一体化;整合各地4S店的资源,服务客户,实现试车预约,保养预约,到点提车;2018上线汽车金融服务;提供以粉丝营销及线下零售体验场景的 o2o 粉丝体验平台

招商银行旗下的项目:开车啦APP
开车啦APP是招商银行旗下的项目:是一款为车主定制的一站式服务平台。根据个性化用车数据,为车主打造生活用车场景的“附近生态圈”,提供便捷、优惠、安心的用车体验:加油,汽车美容,停车,违章查询等服务
提供解决方案
基于商城产品构建B2B2C的平台,满足一部手机完成汽车机油,洗车保养, 查积分, 停车等全方位智能服务;整个O2O平台包含APP、微信小程序等多段实行不同商品上架的功能;O2O方案,门店商品展示;线下推广,线上购物;线上下单,线下服务;线下门店可以绑定商家,核销用户想说购买的产品,提供服务。门店于商家之间可以是多对多的关系;提供全面的商品、用户、订单、销售、市场营销、促销、预约、支付等功能应用的解决方案;实行实物商品和虚拟商品的结合;提供功能更加丰富和强大的后台业务管理工具,便于企业运营团队更加灵活高效的开展线上和线下的业务;通过中台的方案和招行的,用户中心、营销中心、乐视金融平台等系统进行实时无缝对接
实施效果
项目1期加油,汽车美容券,违章查询等已经上线;整合了中经汇通等商家进驻了该平台;线下门店服务也已经遍布全国各地有400多家;二期的实物商品等正在开发之中

微服务架构农业生鲜B2C商城
朗尊软件为群牛搜鲜打造的B2C商城基于目前电商交易和产品特点,借鉴市场主流电商平台模式而设计搭建而成,务求为广大消费者提供产品优良、供应及时、交易便捷、服务精准、监督到位的“一站式”购物体验
提供商城解决方案
项目基于微服务dubbo 产品进行构建;B2C整体解决方案(电商业务需求分析报告,高并发、大流量的运维方案,电商仓储方案,秒杀抢购方案,电商系统性能测试方案等);B2B企业购方案(企业级客户福利平台、专属企业购物通道、企业级客户管理、企业级意向单、定制机业务等); O2O方案(线上下单,到附近自提点自提和创新的集中仓库配送等多种类型线下向线上采购);电商交易系统安全方案
实施效果
2018年7月30日,犇牛微服务架构农业生鲜电商B2C 正式上线;每日UV访问量均4万多,近1000单的交易量;2019年5月8日,犇牛微服务架构农业生鲜电商B2B 正式上线,正式无服务企业商家;商品:6000+,有一批明星单品;服务:北上广生鲜当日达,全国白城配送生鲜;口碑:优质食品代名词,明星单品竞相传播;物流:自建3大仓储,冷链配送;供应链:深入源头的买手团队,基地直采,国际直采

混凝土交易平台
2017年6月,由广州万链信息科技有限公司成立发起和运营,为国内混凝土、新型和环保建材产品的生产、经销企业提供便捷的电子商务渠道,是集商品交易、金融居间服务、支付结算为一体的综合性平台
提供解决方案
提供B2B电商解决方案;灵活的B2B企业级的结算方式;针对企业客户提混凝土及原材料采购管理系统;高效的仓储运营体系,根据不同地区的客户,订单分拆,闪电配送;专门针对混凝土行业资金的三角债问题,提供了企业信贷金融的方案
实施效果
2018年1月商混站正式上线PC版本;2018年5月商混站的手机版本也正式上线;企业订单成交额每年高达3.5亿金额;企业获得融资金额也有到6000万

湖南中烟和+商场
湖南中烟工业有限责任公司前身系成立于2003年的湖南中烟工业公司,隶属国家烟草专卖局(中国烟草总公司)。湖南中烟有巨大的会员群体和庞大的积分体系,为解决闲置的积分,盘活沉睡的流量,湖南中烟携手LegendShop倾力打造了和+商场,用于用户消费积分
提供解决方案
和+商城的用户积分和中烟旗下其他各大商城的积分实现互通,各商城之间的积分、用户、订单信息同步更新。可通过阿里巴巴平台发货,订单状态同步更新;除了实物商品的销售,还有虚拟商品的交易;API服务化,对外提供接口服务;代码优化,减少不必要的循环和复杂的操作;算法优化,使之更高效;功能实现逻辑优化,变得更简洁和清晰;提供大数据分析,对接阿里的Data V-让运营人员对用户分析和订单分析更精准
实施效果
2017年10月 中烟和+积分商城已经上线;满足中烟性能要求:大并发首页单台机器6000并发访问;大并发预约单台;机器1000并发访问;拥有活跃用户高达1000万












获取专业电商解决方案
立即咨询

